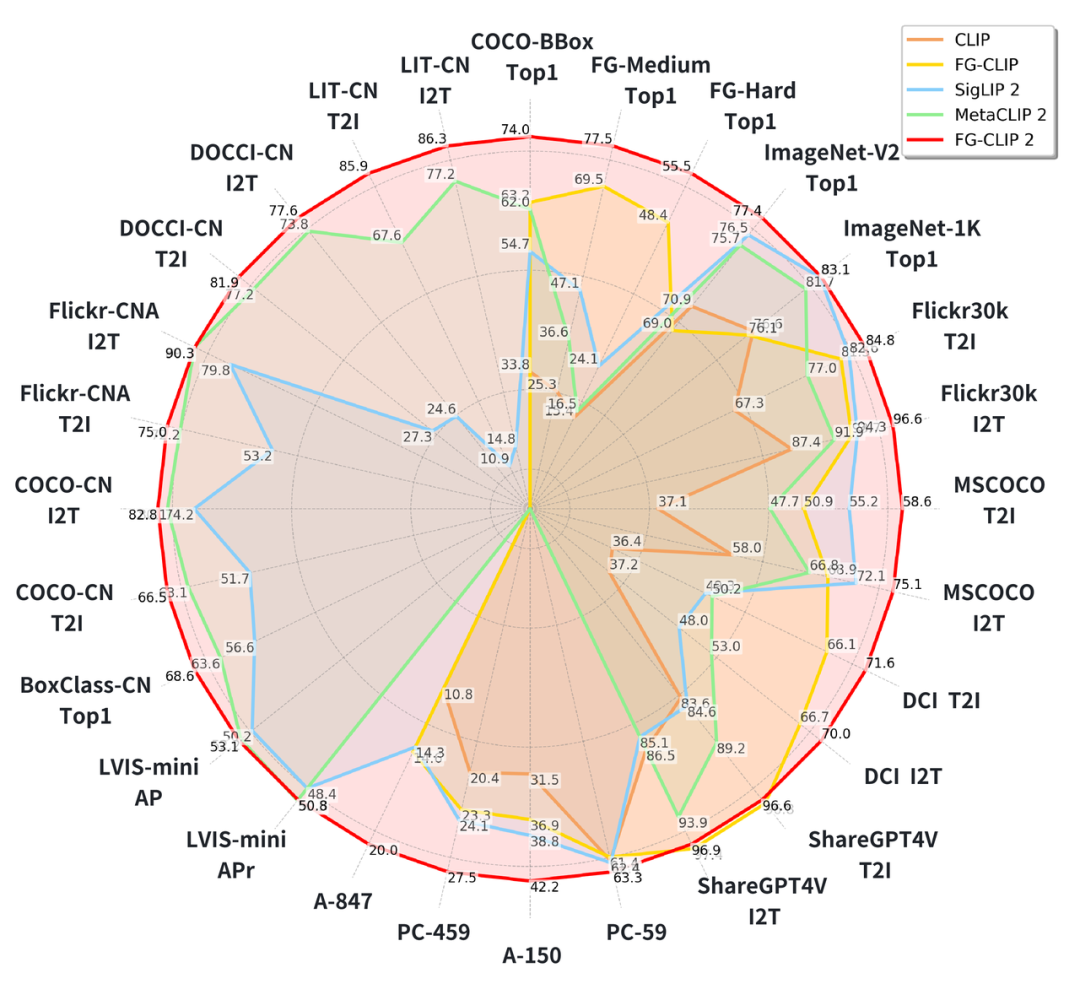
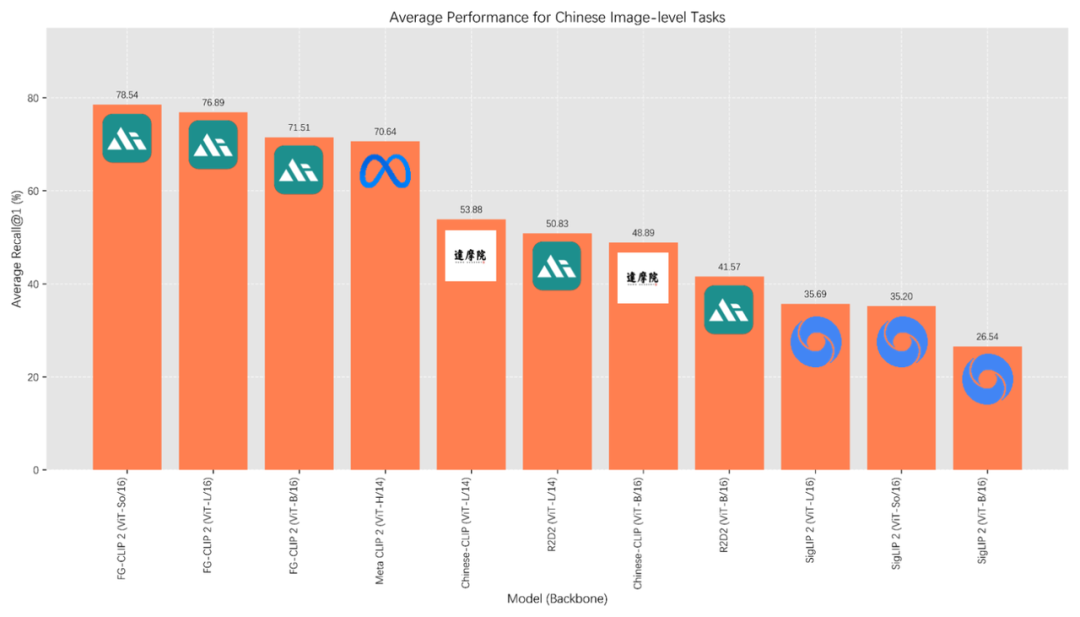
据悉,在长短文本图文检索、OVD目标检测、局部图像分类、全局图像分类多达29个公开基准测试中,FG-CLIP2全面超越Google的SigLIP 2与Meta的MetaCLIP2,成为目前性能最强的图文跨模态视觉语言模型(VLM)。
FG-CLIP 2性能雷达图
中文benchmark综合排名
更值得关注的是,FG-CLIP2攻克了CLIP模型长期存在的“细粒度识别”问题,实现了AI在视觉与语言理解上从“看得见”到“看得清”的跨越。
如果说CLIP给AI配了一副普通的眼镜,让它能看清世界;那么FG-CLIP2就是给它配了一副‘高精度光学显微镜’,让它能洞察入微。
什么是FG-CLIP2
为什么它如此重要?
在深入FG-CLIP2之前,我们有必要了解一个背景:
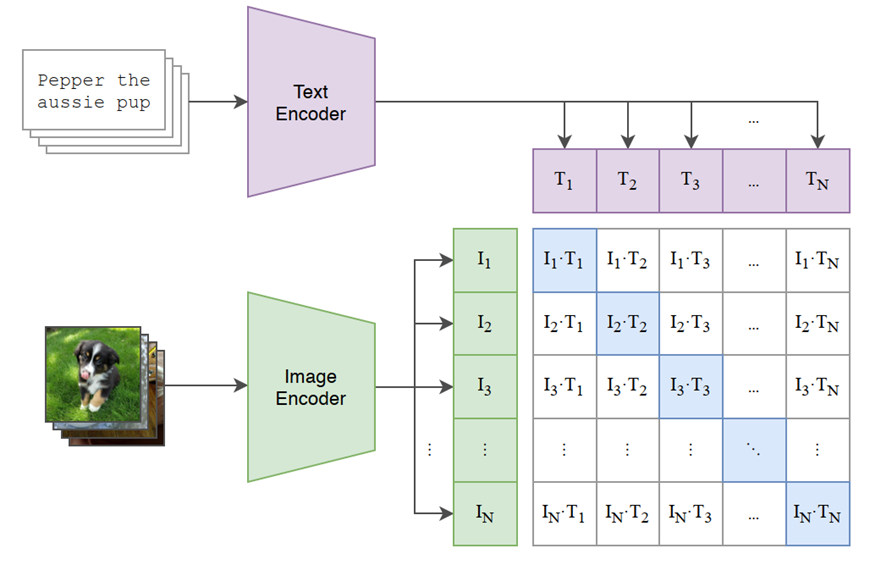
CLIP是由OpenAI在2021年提出的开创性模型。它的核心思想是通过对比学习,将图像和文本在同一个语义空间中对齐。
这意味着,CLIP不是为特定任务(如猫狗分类)训练的,而是学习图像的“通用视觉概念”,并用自然语言来理解和描述它们。这一范式转变,为后来的多模态大模型和文生图、视频大模型(如DALL-E、Stable Diffusion)奠定了关键基础。
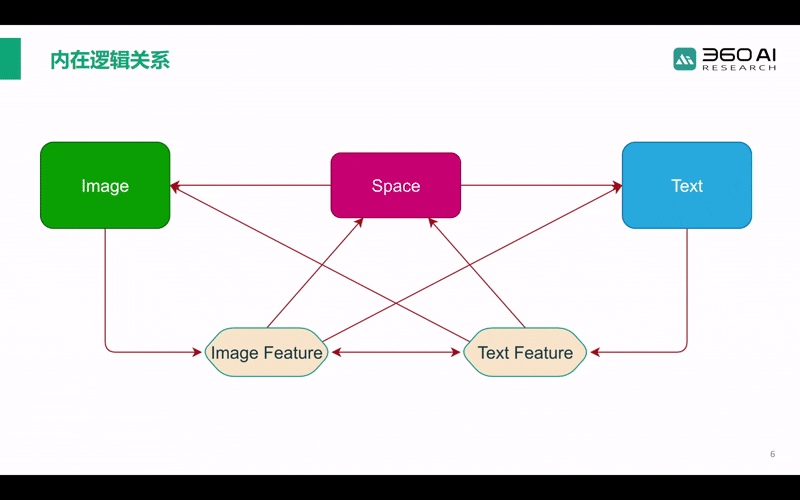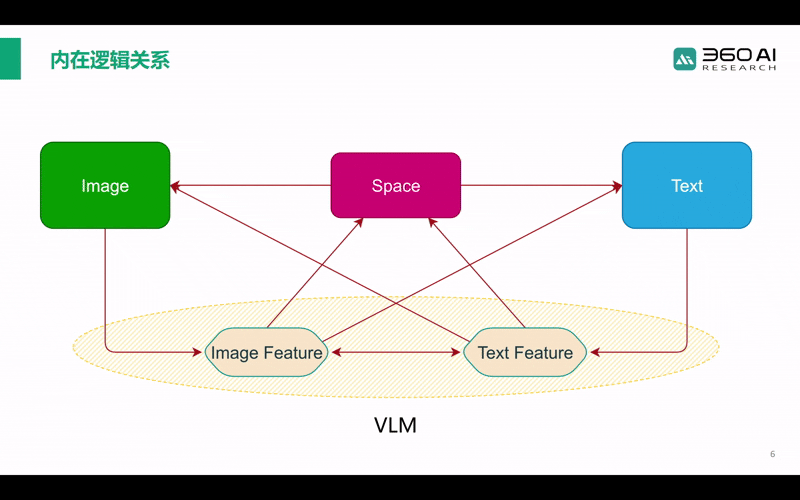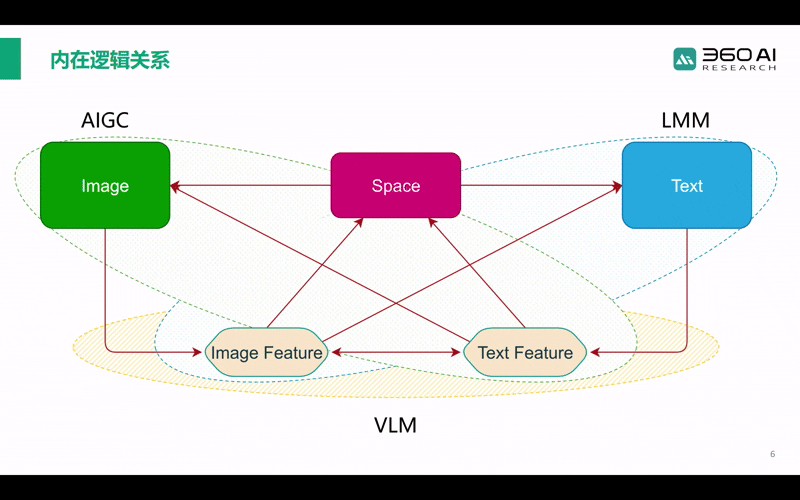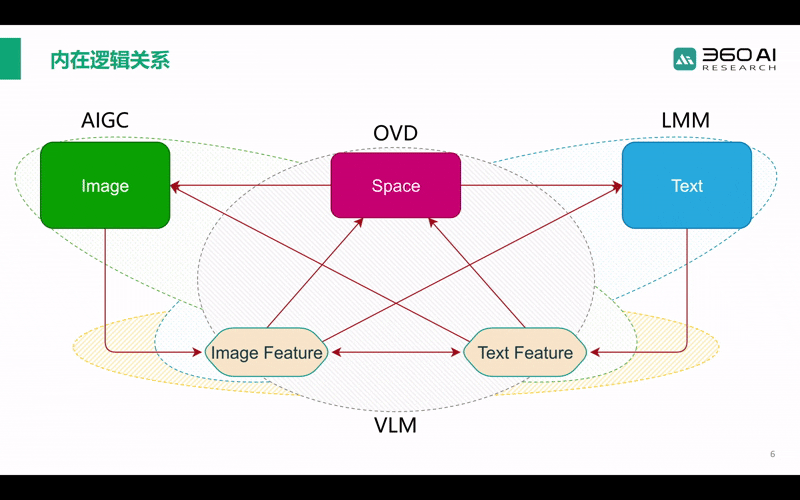
另外,CLIP为代表的跨模态VLM模型主要研究图像特征与文本特征的对齐。当研究对象变成图像特征到文本描述的生成时,就对应多模态大语言模型LMM;而作为LMM的对偶问题,AIGC生成模型则主要研究如何从文本特征实现图像的生成;当关注点转移为从图文特征到空间模态的对应时,对应的就是在安防、自动驾驶和具身智能中极为关键的开放世界目标检测OVD模型。
也可以说,CLIP属于基础模型,它的性能决定了AIGC、LMM等模型的能力上限。
然而,以往的CLIP 模型虽然在全局对齐任务上表现良好,但在需要区分细微物体属性、空间关系和复杂语言表达的任务上容易失分,尤其是中文理解方面更是薄弱。
FG-CLIP 2 针对这些问题,通过丰富的细粒度监督信号和多个判别目标,大幅提升了模型对细节的捕捉和中英文双语的兼容能力。
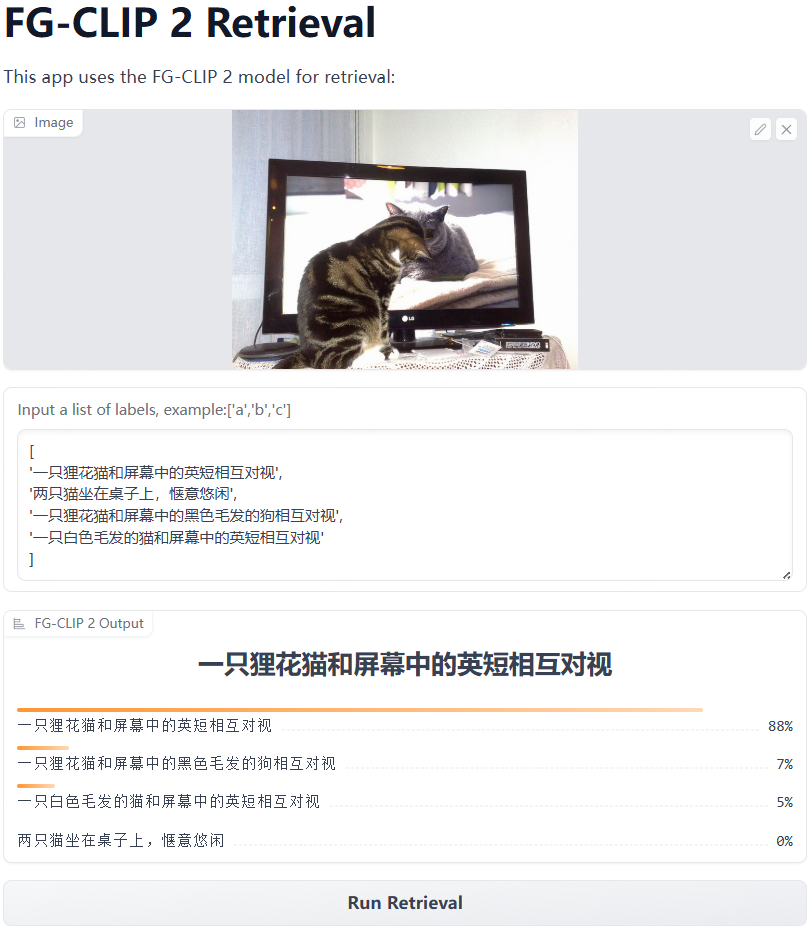
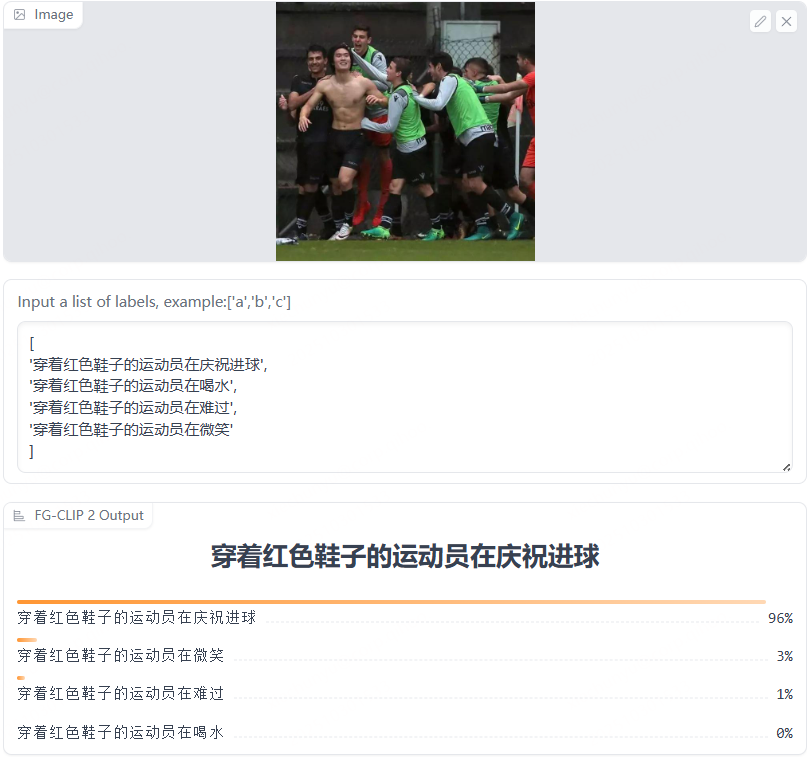
我们来看两张图,可以直观感受这种能力跃进:
图1: FG-CLIP2可以辨别出猫的种类、在遮挡情况下看清猫的状态,甚至在平面结构下,能识别出一只猫在屏幕前,一只在屏幕里。
图2:当图像中包含多个物体或复杂场景时,重要细节往往被背景信息淹没,FG-CLIP2仍能以96%的置信度准确识别出正确的文本描述。
三重创新
构筑技术护城河
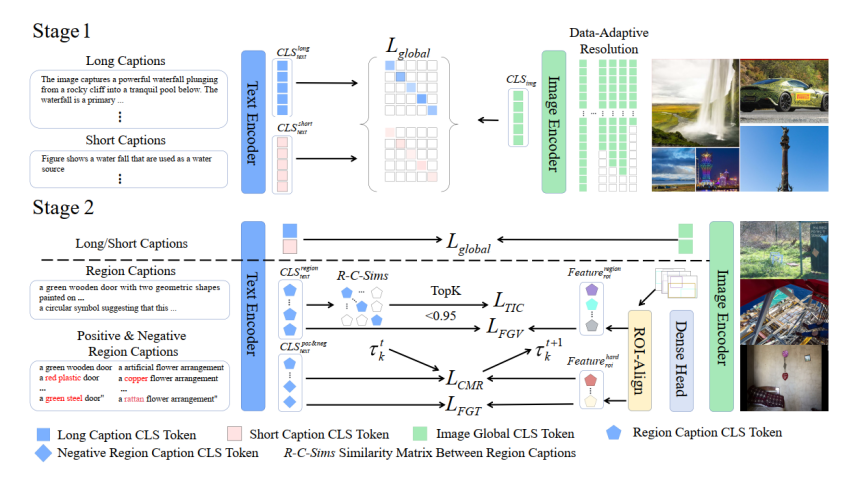
为了让FG-CLIP2实现真正的局部理解和像素级对齐,360人工智能研究院在模型训练最基础的环节:数据、方法和架构等,都进行了系统性的重构。
高质量数据集—FineHARD
数据是模型成功的基石。训练数据覆盖了大规模中英文数据,英文部分基于增强版 LAION-2B,中文则整合了 Wukong、Zero 以及 360 AI Research 自有的 5 亿对大规模数据。
第二阶段更有专门的细粒度区域-文本对齐数据,涵盖千万级样本。为填补中文评测空白,团队还自建了 LIT-CN、DCI-CN、DOCCI-CN 等长描述检索集和 BoxClass-CN 区域分类集,实现了对模型多维度、双语细粒度能力的全面评估。
全局细粒度对齐:不仅包含了常规的图像“短文本”描述(平均长度约20个词),还为每张图像生成包含场景背景、对象属性及空间关系等详细信息的“长文本”描述(平均长度 150个词+),显著提升了全局语义密度。
局部细粒度对齐:每张图像包含基于开放世界目标检测模型提取的目标实体的位置,即为每个目标区域对应的region描述。数据集包含高达4000万个bounding box及其对应的区域级细粒度描述文本。
细粒度难负样本:基于细节属性扰动方法,利用LLM模型为FineHARD数据集构造并清洗出了1000万组细粒度难负样本。大规模难负样本数据是FineHARD数据集区别于已有数据的重要特点。
训练方式的“全局+局部”策略
与CLIP的粗粒度对齐训练方法(图像整体与文本整体信息对齐)相比,FG-CLIP 2在训练方法的核心创新体现在基于OVD和LMM的技术积累,实现了图像局部信息与文本局部信息的对齐,从而解决了以CLIP为代表的第一代跨模态VLM模型对齐粒度粗糙的本质缺陷。
具体来说,FG-CLIP 2采用了两阶段的训练策略:
Stage1为预训练,采用与CLIP相同的整体信息对齐训练策略,来实现初步的图文语义对齐;这一阶段与CLIP的关键区别是,我们在普通的噪声较高的互联网短文本之外,为图像增加了对应的包含详细细节描述的长文本,通过数据层面的关键改变,为stage2的细粒度对齐打下初步基础。
Stage2为关键的细粒度对齐训练,这里不再采用CLIP的整体对齐策略,而是采取图像局部信息与文本局部信息对齐的训练策略,这一步是FG-CLIP 2能够实现图文细粒度理解的关键方法。
动态分辨率 + 中英双语支持
在视觉处理部分,FG-CLIP 2采用数据自适应分辨率策略:根据每批次图像的最大尺寸,从128, 256, 576, 784, 1024中选择目标分辨率,避免如SigLIP 2的随机采样机制带来的图像变形过大的问题,确保训练与推理行为的一致性,同时将图像放大或缩小操作降至最低。
为了更好的适配中英双语,在两阶段的训练中均精选了大规模、高质量的中英文数据,使得模型能够充分的学习两种原生语境。
FG-CLIP 2模型不是简单的实验室研究,已经以“API+MCP”形式开放,无论是互联网搜广推、智能办公检索,还是复杂场景下的视觉分析,FG-CLIP 2都将以“眼观六路、洞察细节”的领先能力,为开发者与企业用户提供稳定、易用和强大的跨模态智能服务。
告别“差不多”AI
细粒度视觉撬动产业新支点
作为视觉基石模型,FG-CLIP 2通过提升对图像中局部区域、物体属性、空间关系与语义细节的跨模态理解能力,显著增强了图文匹配的精度与场景适应性,为千行百业的智能化升级提供关键支撑。
图文检索
FG-CLIP 2可实现“以文搜图”的精准定位,例如根据“穿红色裙子、手持咖啡杯、站在商场玻璃门前的女性”这类复杂描述,准确检索出目标图像。相比传统CLIP仅匹配整体语义,细粒度版本能捕捉关键局部特征,提升识别准确率。
AIGC内容生成
可作为生成模型的反馈或控制信号,确保生成内容在细节层面与文本提示高度一致。例如,在广告图像生成中,保障品牌LOGO位置、产品颜色、文案布局等关键元素的精确呈现,避免“生成偏差”或“品牌失真”,提升内容可用性。
内容审核
细粒度理解能力使模型能识别敏感或违规的局部信息,如特定人物、标志、不当文字或隐喻性图像组合,而不仅依赖整体图像分类。这对于社交平台、直播、UGC内容的合规性审查具有重要意义,尤其在应对“打擦边球”类内容时更具优势。
安防监控
FG-CLIP2可支持自然语言驱动的视频检索,如“寻找背着黑色双肩包、穿蓝色T恤的男子”,实现快速线索定位,提升应急响应效率。其跨模态能力降低了对结构化标签的依赖,适用于复杂、动态的监控场景。
具身智能
可帮助机器人准确理解细粒度语言指令。例如,执行“拿餐桌上的红色水杯”时,能区分多个杯子中的目标;或在“把玩具放进绿色收纳箱”任务中,精准识别颜色和容器。相比普通CLIP,它更能理解“脏的抹布”“打开的抽屉”等状态描述,提升机器人在家庭、仓储等场景中感知与操作的准确性。
目前FG-CLIP2已在360集团的多个核心业务中落地,包括广告图像匹配、IoT摄像机场景识别与360云盘图片搜索。模型在高并发场景下稳定运行,延迟可控在毫秒级,验证了其在真实商业环境中的工程可靠性。细粒度CLIP不仅是模型能力的提升,更是推动AI从“看得见”向“看得懂”跃迁的关键一步,为各行业实现高精度、可解释、语义丰富的视觉智能应用奠定坚实基础。
构建自主AI核心能力
360的AI长期主义
FG-CLIP2的成功并非偶然,它源于360在AI底层能力建设上的长期投入与坚持。
作为一家拥有浏览器、安全、搜索、广告、AI助手等完整生态的科技企业,360深知:没有统一而强大的AI底层能力,就难以支撑未来智能化生态的发展。因此早在2015年,360便成立了人工智能研究院,开始系统性地构建技术基础。
在2021年,当全球的目光还聚焦于ChatGPT的语言能力时,360人工智能研究院已着手探索“AI如何看懂图像、理解空间、识别语义关系”等更深层的问题。如今,360已构建起一个覆盖视觉、语言、知识与智能应用的全方位技术版图。旗下FG-CLIP、LMM-Det、360VL、SEEChat、HiCo、PlanGen等核心模型,不仅代表了前沿科研水平,也广泛应用于产业实践。
截至目前,研究院累计已有12篇论文被ICLR、ICCV等国际顶级会议收录,并在多项人工智能基础科研竞赛中取得领先成绩。
再加上360依托其在搜索、安全、浏览器等业务场景中积累的百亿级图文数据,并结合自研的大规模高质量数据集FineHARD。这种规模和数据多样性,为基础模型的研究奠定了坚实基础。
其次是工程能力。360人工智能团队在模型优化和落地方面积累了丰富经验,这让FG-CLIP2不仅在精度上领先,更在推理速度上达到同类模型的1.5倍。“技术在实验室里领先是一回事,能在实际业务中稳定运行是另一回事。”团队技术负责人强调。
FG-CLIP2的突破,不仅是360AI领域的研发实力,更是中国企业在基础模型领域持续创新的证明。这种在基础技术上的深耕,将为构建自主可控的AI技术体系提供重要支撑。
开源优配提示:文章来自网络,不代表本站观点。